索引与B+树
为什么InnoDB使用B+树作为索引的数据结构?
为什么不用哈希表?
众所周知,哈希表理想的插入和查询时间复杂度为$O(1)$,也就是说,如果不发生冲突,哈希表就是永远滴神。那么为什么哈希表不是理想的索引结构?
1 | SELECT * FROM User WHERE id = 1; |
假如是这么一个SQL语句,那么用哈希表作为id列的索引可以说几乎是完美的。因为id一般来说都是主键,id为1的行肯定只有1个。
1 | SELECT * FROM User WHERE id > 1; |
但假若是这么一个需要进行范围搜索的SQL命令,哈希表就白给了,因为对于id>1这么一个范围条件来讲,你哈希函数怎么做映射?
InnoDB是存在自适应哈希索引的,但正如上述所说,对于字典型,哈希索引效率是很高的,但对于范围性搜索,哈希表是无能为力的。
为什么不用AVL?
哈希表不理想,是因为无法较好支持范围查询,但二叉树可以啊。那为什么InnoDB也没有采取此种方式?
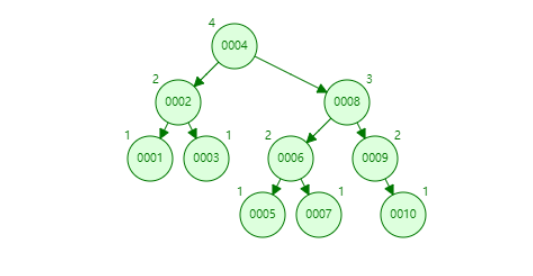
这是一个插入了1-10的AVL树,假设我们运行下面这个SQL
1 | SELECT * FROM User WHERE id > 5; |
在AVL中,先锁定节点5的位置,所有大于5的节点都分布在它的右方。那么我们在进行查询的时候,就需要DFS来对所有键值大于5的节点进行访问并输出,那么这显然会增加磁盘的随机I/O次数,因为我们不可能把整个索引结构全加载进内存,所以这种索引查找避免不了频繁的磁盘I/O,磁盘随机I/O的时间消耗可是致命的,这种徒增I/O消耗的方法对于数据库来讲肯定是不可取的。
为什么不用B树?
减少上述I/O次数的一种办法就是降低树的高度,怎么降低高度?每个节点多存点数据就行了。B树就这么诞生了。
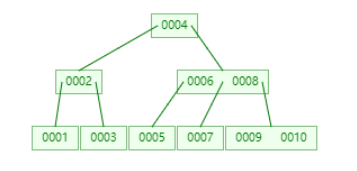
这是一个max degree为3的B树,同样是插入1-10,B树的高度要小于AVL树。但这依然解决不了需要DFS的问题,随机I/O消耗依旧不小。
那为什么就用B+树了?
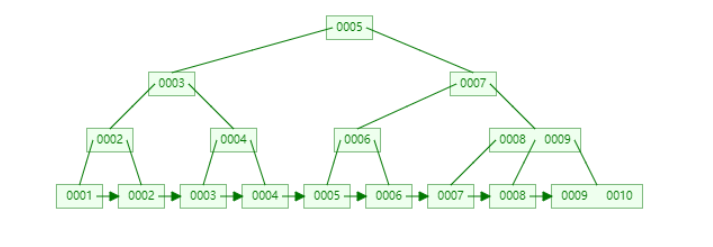
上图是一个max degree也为3的B+树,B+树不同于B树的地方就在于所有数据都存在于叶子节点,非叶子节点只包含键值,不包含数据。最早在数据结构课上看到B+树的时候,我一直不明白这东西存在的意义是什么,同样的数据同样的max degree,B+树的高度明显要比B树大,那为什么InnoDB会采用B+树?还是因为随机I/O的问题,B+树所有的叶子节点会构成一个链表结构,每个节点都拥有指向下一个节点的指针,这样在进行范围搜索的时候,B+树就可以直接在叶子节点之间进行跳转,这样大大减少了磁盘I/O的所消耗的时间。同时,若链表数据能够连续存储,不但节省I/O,还能保证数据在逻辑上和物理上都是相邻的,这恰恰适用于局部性原理,对于内存页表的缓存非常友好。
索引失效
B+树用于索引的优势就在于1)二分查找加速查找时间。2)叶子节点按顺序排列,链表结构优化范围查找。所以但凡SQL语句的查询条件使得查询时无法遵守叶子节点的排列顺序,索引就失效了。
带OR的SQL
当SQL的条件带有OR关键字,自然查找就不会遵循叶子节点的排列顺序,因为OR连接的两个条件所对应的叶子节点在B+树的叶子链表中不一定是连续的,如果是跳跃的,B+树自然就没用了,就只能全表扫描进行查找。
组合索引
如果索引是组合索引,例如下图的B+树叶子节点链表:
1 | +-------+ +-------+ +-------+ +-------+ +-------+ +-------+ |
可见,叶子节点的排列顺序是先排列第一个key,再排列第二个key,如果只用key2作为条件:
1 | SELECT * FROM User WHERE key2>2; |
因为在叶子节点中,key2的排列顺序是依赖于key1的,只看key2的话,key2是无序的。所以如果单纯只以key2来作为条件,搜索时无法按照叶子节点的链表顺序来进行查找,索引失效。
但假如先设置key1条件,再设置key2条件:
1 | SELECT * FROM User WHERE key1=1 AND key2>2; |
这样是符合链表顺序的,索引就不会失效。
如果把key2和key1顺序颠倒,会先去搜寻符合key2条件的节点,再去搜寻也符合key1的节点。但是组合索引的顺序是(key1, key2),顺序依然会被打乱,所以索引仍会失效。例如:
1 | SELECT * FROM User WHERE key2=1 AND key1=1; |
如果key1的条件是一个范围,即使遵循先key1再key2的顺序,索引依然会失效。例如:
1 | SELECT * FROM User WHERE key1>1 AND key2=1; |
原因也很显然,因为key1>1筛选出来的是一个范围,在这个范围内,key2仍是无序的,所以依然会造成遍历部分链表。
为了避免组合索引下的索引失效,需要SQL中的条件语句遵守最左前缀法则,即,条件语句中的各条件顺序应按照组合索引的顺序,且在最后一个条件之前不得出现范围查询(>, <, between, in等)。例如上面第二个SQL语句,只有最后对于key2的条件是指定范围。
like模糊搜索
like后的字符串模糊匹配分为前缀、中缀和后缀三种,即,str%,%str%,%str。对于判断哪种会造成索引失效,同上面的思路,只要保证搜索时能按照叶子节点的链表顺序,就不会出现整表搜索的情况。对于字符串类型的数据,其叶子节点是按照字典序来排列的,那么答案就很明朗了,只有前缀,即str%这种形式的模糊搜索是不会破坏索引的,其余的中缀和后缀,都无法保证字典序搜索,自然会造成索引失效。
对索引列进行运算或者函数操作
如果对索引列的数据进行了一些运算操作或者函数操作,其结果值自然无法应用于现有的B+树结构,索引自然也就失效了。